# 整型
整型分为以下两个大类:
- 有符号类型,按长度分为:
int8、int16、int32、int64 - 无符号类型,与上面对应的分别是:
uint8、uint16、uint32、uint64
这里
unit8就是我们熟知的byte型,int16对应 C 语言中的short型,int64对应 C 语言中的long类型。
var e1 int8 = 1 //定义一个int8类型
var e2 int16 = 1 //定义一个int16类型
var e3 int32 = 1 //定义一个int32类型
var e4 int64 = 1 //定义一个int64类型
var e5 uint8 = 1 //定义一个uint8类型
var e6 uint16 = 1 //定义一个uint16类型
var e7 uint32 = 1 //定义一个uint32类型
var e8 uint64 = 1 //定义一个uint64类型
2
3
4
5
6
7
8
# 自动匹配平台的 int 和 unit
有一种类型,它能根据平台 CPU 机器字节大小来调整长度:
- 有符号类型:
int - 无符号类型:
uint
这里 int 是应用最广泛的数值类型。这两种类型都有同样的大小,32 或 64bit,但是我们不能对此做任何的假设, 因为不同的编译器即使在相同的硬件平台上可能产生不同的大小。
var e int = 18; //定义一个int
var ue uint = 18; //定义一个uint
2
# 什么情况要使用 int 和 unit
实际应用中,切片或者 map 的元素数量均可通过 int 来表示。
但是,在二进制传输、读写文件的结构描述时,为了保证文件的结构不受不同编译目标平台的字节长度影响,不要使用 int 和 unit。
# 整数类型 uintptr
一种无符号的整数类型 uintptr,它没有指定具体的 bit 大小但是足以容纳指针。uintptr 类型只有在底层编程时才需要,特别是 Go 语言和 C 语言函数库或操作系统接口相交互的地方。
尽管在某些特定的运行环境下 int、uint 和 uintptr 的大小可能相等,但是它们依然是不同的类型,比如 int 和 int32,虽然 int 类型的大小也可能是 32 bit,但是在需要把 int 类型当做 int32 类型使用的时候必须显示的对类型进行转换,反之亦然。
Go 语言中有符号整数采用 2 的补码形式表示,也就是最高 bit 位用来表示符号位,一个 n-bit 的有符号数的取值范围是从 -2(n-1) 到 2(n-1)-1。无符号整数的所有 bit 位都用于表示非负数,取值范围是 0 到 2n-1。例如,int8 类型整数的取值范围是从-128 到 127,而 uint8 类型整数的取值范围是从 0 到 255。
# 浮点型
Go 语言中提供了两种精度浮点型 float32 和 float64。这两种浮点型数据格式遵循 IEEE754 浮点数国际标准,该浮点数规范被所有现代的CPU支持。
# 浮点型 Float32
float32,即我们常说的单精度,存储占用4个字节,也即4*8=32位,其中1位用来符号,8位用来指数,剩下的23位表示尾数。
# 浮点型 Float64
float64, 即我们熟悉的双精度,存储占用8个字节,也即8*8=64位,其中1位用来符号,11位用来指数,剩下的52位表示尾数。
# 浮点数精度
float32 的浮点数最大值约为 3.4e38, 可以通过 match包的方法来获取: match.MaxFloat32。
float64 的浮点数最大值约为 1.8e308, 可以通过 match包的方法来获取: match.MaxFloat64。
它们分别能表示的最小值近似为1.4e-45和4.9e-324。
一个float32类型的浮点数可以提供大约6个十进制数的精度,而float64则可以提供约15个十进制数的精度;通常应该优先使用float64类型,因为float32类型的累计计算误差很容易扩散,并且float32能精确表示的正整数并不是很大(注意:因为float32的有效bit位只有23个,其它的bit位用于指数和符号;当整数大于23bit能表达的范围时,float32的表示将出现误差)
var f float32 = 16777216 // 1 << 24
fmt.Println(f == f+1) // "true"!
2
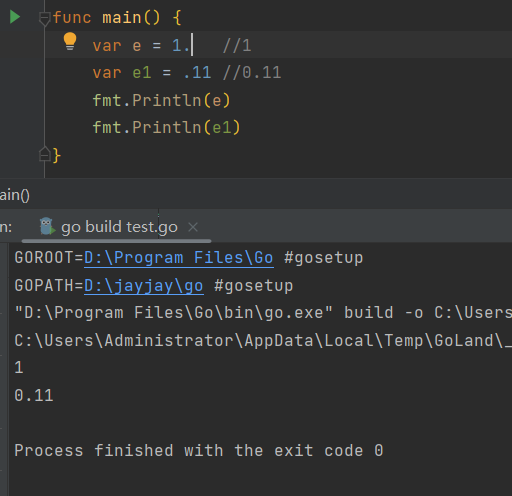
浮点数的字面值可以直接写小数部分,小数点前面或后面的数字都可能被省略(例如.707或1.)如下所示:
var e = 1. //1
var e1 = .11 //0.11
fmt.Println(e)
fmt.Println(e1)
2
3
4
很小或很大的数最好用科学计数法书写,通过e或E来指定指数部分:
const Avogadro = 6.02214129e23 // 阿伏伽德罗常数
const Planck = 6.62606957e-34 // 普朗克常数
2
# 打印浮点数
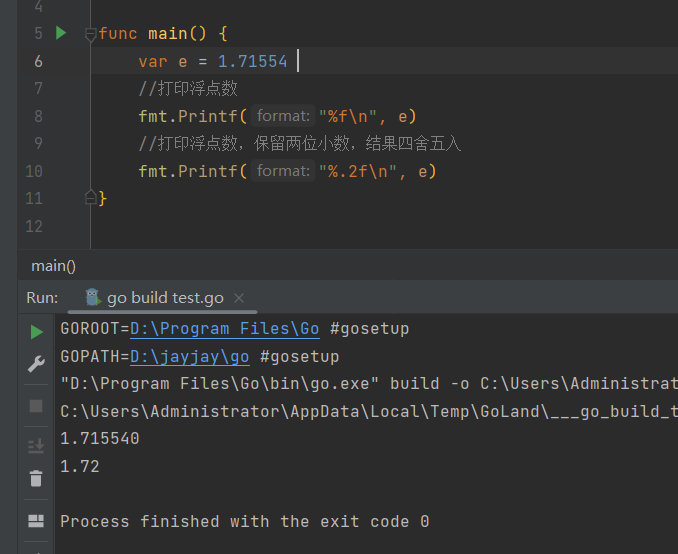
通过 Printf 函数打印浮点数时, 可以使用%f来控制保留几位小数, 代码如下:
package main
import "fmt"
func main() {
var e = 1.71554
//打印浮点数
fmt.Printf("%f\n", e)
//打印浮点数,保留两位小数,结果四舍五入
fmt.Printf("%.2f\n", e)
}
2
3
4
5
6
7
8
9
10
11
# 布尔型
布尔类型只有 true 和 false 两种值,以关键字 bool 来声明。
var a bool = true //定义一个值为true布尔型
var b bool = false //定义一个值为false布尔型
2
if 和 for 语句的条件部分都是布尔类型的值,并且 == 和 < 等比较操作也会产生布尔型的值。一元操作符!对应逻辑非操作,因此!true的值为false,更罗嗦的说法是(!true==false)==true,虽然表达方式不一样,不过我们一般会采用简洁的布尔表达式,就像用 x 来表示x==true。
var a bool = true
//如果a==true就进入代码块
if a==true {
//codeing
}
2
3
4
5
布尔值可以和 &&(AND)和||(OR)操作符结合,并且有短路行为,如果运算符左边值已经可以确定整个布尔表达式的值,那么运算符右边的值将不再被求值。
布尔类型无法参与数值运算,也无法与其他类型进行转换
var a bool = false
fmt.Println(int(a))
2
会报错:
cannot convert a (type bool) to type int // 无法将 bool 类型转换为 int 类型
# 字符串
在 Go语言中,字符串是一个不可改变的字节序列,类型为原生数据类型,同 int 、bool、float32 、float64 是一样的。
字符串的值通过双引号来包裹,Go 语言中,我们可以直接添加非 ASCII 码字符, 代码如下:
str := "hello world"
# 计算字符串的长度
Go 语言内置的 len()函数可以字符串的长度。
package main
import "fmt"
func main() {
str1 := "hello world"
fmt.Println(len(str1))
}
2
3
4
5
6
7
8
9
代码运行结果如下:
11
len()函数返回值为 int 类型,表示字符串的 ASCII 字符的个数或字节长度。
但是中文比较特殊,因为 Go 语言的字符串都以 UTF-8 格式保存,每个中文占用 3 个字节,所以下面是3 x 2 = 6 个字节。
package main
import "fmt"
func main() {
str1 := "你好"
fmt.Println(len(str1))
}
2
3
4
5
6
7
8
9
10
代码运行结果如下:
6
但是如果我们想要统计有多少个中文的时候该怎么办呢,那就要使用 UTF-8 包提供的 RuneCountInString() 来统计 Uncode 字符数量:
package main
import (
"fmt"
"unicode/utf8"
)
func main() {
str1 := "你好"
fmt.Println(utf8.RuneCountInString(str1))
}
2
3
4
5
6
7
8
9
10
11
12
13
代码运行结果如下:
2
# 遍历字符串
# ASCII字符遍历
遍历 ASCII 字符通过 for 循环来,使用字符串的下标来获取,代码如下:
package main
import "fmt"
func main() {
str := "abcdefg"
for i := 0; i < len(str); i++ {
//输出字符,和ascii码对应的数字
fmt.Printf("ascii: %c %d\n", str[i], str[i])
}
}
2
3
4
5
6
7
8
9
10
11
12
代码输出如下:
ascii: a 97
ascii: b 98
ascii: c 99
ascii: d 100
ascii: e 101
ascii: f 102
ascii: g 103
2
3
4
5
6
7
# 按Unicode 字符遍历字符串
如果用fori的形式,会导致中文乱码:
package main
import (
"fmt"
)
func main() {
str := "你好,GO"
for i := 0; i < len(str); i++ {
fmt.Printf("ascii: %c %d\n", str[i], str[i])
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
代码输出如下:
ascii: ä 228
ascii: ½ 189
ascii: 160
ascii: å 229
ascii: ¥ 165
ascii: ½ 189
ascii: ï 239
ascii: ¼ 188
ascii: 140
ascii: G 71
ascii: O 79
2
3
4
5
6
7
8
9
10
11
想正常遍历的话要用for range的方式,这样就不会乱码了:
package main
import (
"fmt"
)
func main() {
str := "你好,GO"
for _, s := range str {
fmt.Printf("Unicode: %c %d\n", s, s)
}
}
2
3
4
5
6
7
8
9
10
11
12
13
代码输出如下:
Unicode: 你 20320
Unicode: 好 22909
Unicode: , 65292
Unicode: G 71
Unicode: O 79
2
3
4
5
# 获取字符串某一段字符
可以通过 str[i:j] 基于原始的 str字符串的第 i个字节开始到第 j 个字节(并不包含 j本身)生成一个新字符串。生成的新字符串将包含 j-i 个字节。
package main
import (
"fmt"
"strings"
)
func main() {
str := "abcdefg"
fmt.Println(str[0:1]) // 输出 a
// 通过 strings.Index() 函数获取字符 . 的下标
index := strings.Index(str, "e")
fmt.Println(str[0:index]) // 输出 adcd
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
代码输出如下:
a
abcd
2
如果索引超出字符串范围或者j小于i的话将导致panic异常。
不管i 还是 j都可以不填写,若不填写,将采用0作为开始位置,采用len(s)作为结束的位置。
package main
import (
"fmt"
)
func main() {
str := "abcdefg"
fmt.Println(str[0:1]) // 输出 a
fmt.Println(str[:3]) // "abc"
fmt.Println(str[4:]) // "efg"
fmt.Println(str[:]) // "abcdefg"
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
strings.Index: 正向搜索子字符串,并获取下标位置;
strings.LastIndex: 反向搜索子字符串,并获取下标位置;
# 修改字符串
Go 语言中,同 `Java 一样,字符串默认是不可变的,无法直接修改字符串中的字符,只能通过重新构造一个新的字符串并赋值给原来的字符串实现:
package main
import (
"fmt"
)
func main() {
str := "abcdefg"
// 将字符串转换为字符串数组
strBytes := []byte(str)
// 将 defg 替换为a
for i := 3; i < len(str); i++ {
strBytes[i] = 'a'
}
fmt.Println(string(strBytes))
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
代码输出如下:
abcaaaa
上面代码实际修改的是 []byte, 代码中最后打印输出时,实际上通过 string()将 []byte 转为字符串,重新创造了一个新的字符串。
总结:
Go语言中字符串时不可变的;- 修改字符串时,可以将字符串转换成
[]byte进行修改; []byte和string可以通过类型转换互转。
# 拼接字符串
Go 语言同绝大数其他语言一样,通过操作符 + 可以将两个字符串连接构造一个新字符串:
str1 := "hello "
str2 := "Go"
fmt.Println(str1 + str2) // "hello Go"
2
3
除了使用 + 来拼接字符串,Go 语言中也有类似于 Java 语言中 StringBuilder 的机制,来进行更高效率的字符串拼接, 代码如下:
package main
import (
"bytes"
"fmt"
)
func main() {
str1 := "hello "
str2 := "Go"
// 声明字节缓冲
var stringBuilder bytes.Buffer
// 将字符串写入缓冲
stringBuilder.WriteString(str1)
stringBuilder.WriteString(str2)
// 将缓冲以字符形式输出
fmt.Println(stringBuilder.String())
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
代码输出:
hello Go
bytes.Buffer 做缓冲使用,我们可以通过 WriteString 函数往里面写入各种字节数组。字符串也是一种字节数组。
最后,再通过 stringBuilder.String() 将缓冲转换为字符串。
# 字符串比较
字符串可以用 == 、 <、> 进行比较;比较通过逐个字节比较完成的,因此比较的结果是字符串自然编码的顺序。
package main
import "fmt"
func main() {
str1 := "abc"
str2 := "abc"
// 是否相等标志位
isSame := false
if str1 == str2 {
isSame = true
}
fmt.Println(isSame)
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
代码输出如下:
true
# 字符串转义符
Go 语言中,常见转义符包括回车、换行、单双引号、制表符等:
| 转义符 | 含义 |
|---|---|
\r | 回车符 |
\n | 换行符 |
\t | 制表符 |
\' | 单引号 |
\'' | 双引号 |
\\ | 反斜杠 |
package main
import (
"fmt"
)
func main() {
str := "abc\ndefg" //使用\n换行
fmt.Println(str)
}
2
3
4
5
6
7
8
9
10
代码输出如下:
abc
defg
2
# 定义多行字符串
Go 语言中,字符串双引号的书写方式最为常见,但是不能用来表示多行。如果需要使用多行字符串,需要使用 ` 字符,示例代码如下:
package main
import "fmt"
func main() {
str := `第一行
第二行
第三行
\r\n`
fmt.Println(str)
}
2
3
4
5
6
7
8
9
10
11
12
代码输出如下:
第一行
第二行
第三行
\r\n
2
3
4
PS: 反引号 ` 在键盘上 1 键左边的位置,被反引号包裹的字符串将会被原样赋值给 str 变量。
注意: 被反引号包裹的转义符会被当成正常字符串看待,原样被输出。
# Go 语言字符串格式化常用动词
字符串格式化应用场景十分丰富,格式如下:
fmt.Sprintf(格式化样式, 参数列表)
- 格式化样式: 字符串形式,动词以
%开头; - 参数列表: 多个参数通过逗号隔开,个数需要与格式化样式中的动词一一对应,否则会报错。
常见动词以及功能如下:
| 动词 | 功能 |
|---|---|
%b | 整型以二进制方式显示 |
%o | 整型以八进制方式显示 |
%d | 整型以十进制方式显示 |
%x | 整型以十六进制方式显示 |
%X | 整型以十六进制、字母大写方式显示 |
%T | 输出Go语言语法格式的类型和值 |
%f | 浮点数 |
%p | 指针,十六进制方式显示 |
%v | 按值原本的值输出 |
%+v | 在%v的基础上,对结构体字段名和值进行展开 |
%#v | 输出Go语言语法格式的值 |
%% | 输出%本体 |
%U | Unicode字符 |
下面是一些代码示例:
package main
import (
"fmt"
)
func main() {
a := 1
b := 2
// 两整型参数格式化
fmt.Printf("第一个数: %d, 第二个数: %d\n", a, b)
str1 := "hello "
str2 := "go"
// 两字符串参数格式化
content := fmt.Sprintf("1: %s, 2: %s\n", str1, str2)
fmt.Println(content)
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
代码输出如下:
第一个数: 1, 第二个数: 2
1: hello , 2: go
2
# 字符(byte与rune)
Go 语言中,字符串的每一个元素叫做字符(char),主要分为以下两种:
1、
uint8类型,或者叫byte型,代表了ASCII码的一个字符。提示:
byte类型是unit8的别名。2、
rune类型,代表了一个UTF-8字符。通常情况下,当需要处理中文、日文、韩文等复合字符时,需要用到rune类型。
package main
import "fmt"
func main() {
var a byte = 'a'
fmt.Printf("%d %T\n", a, a)
var b rune = '哈'
fmt.Printf("%d %T\n", b, b)
}
2
3
4
5
6
7
8
9
10
11
12
代码输出如下:
97 uint8
21704 int32
2
得出结论:
byte的实际类型其实是个uint8, 对应的 ASCII 编码为 113;rune的实际类型其实是int32, 对应的 Unicode 编码为 29356;
Go 语言中,使用了 rune 类型来处理 Unicode 编码,这样让基于 Unicode 的文本处理更为方便,同时也可以用 byte 进行默认的字符串处理,这样对性能和拓展性都有照顾。
# UTF-8 和 Unicode 有何区别?
Unicode 与 ASCII 都是一种字符集。
字符集为每个字符分配一个唯一的ID,我们使用到的所有字符在Unicode 字符集中都有一个唯一的 ID,例如 a 字符在 Unicode 与 ASCII 中的编码都是 97。汉字哈在 Unicode 中的编码为 21704,在不同国家的字符集中,字符所对应的 ID 也会不同。而无论任何情况下,Unicode 中的字符的 ID 都是不会变化的。
UTF-8 是编码规则,将 Unicode 中的字符 ID 以某种方式进行编码。UTF-8 是一种变长编码规则,从 1 到 4 个字节不等。编码规则如下:
0xxxxxx表示文字符号0~127,兼容ASCII字符集。- 从
128到0x10ffff表示其他字符。
在这种规则之下,拉丁文语系的字符编码一般情况下, 每个字符占用一个字节,而中文每个字符占用 3 个字节。